
Data Science and Machine Learning
Personal Projects
Project Title : Predicting the ambient electrical energy output (PE) of a Combined Cycle Power Plant (CCCP) using Machine Learning algorithms [Prediction]

Image source: unsplash.com/@jeisblack
Project affilation This is a final project done in fulfillment of the Data Science 1 course at the faculty of Electrical and Electronics at Technische Universitaet Darmstadt.
Background
This project aims to predict the ambient electrical energy output (PE) of a Combined Cycle Power Plant (CCCP). By understanding how different conditions affect energy output, operators can adjust settings and configurations to maintain peak efficiency and help in scheduling maintenance and repairs, and avoid potential disasters from overloading. Towards society, effeciciency of the power plant, ensures that consistent electric power is provided. UCI.edu. Features are explained at the next section of the notebook
Key technologies and skills : python, git, github, anaconda-jupyter, vscode, sklearn, pandas, matplotlib, jupyter
Deliverables : The full project workflow and repository can be found here
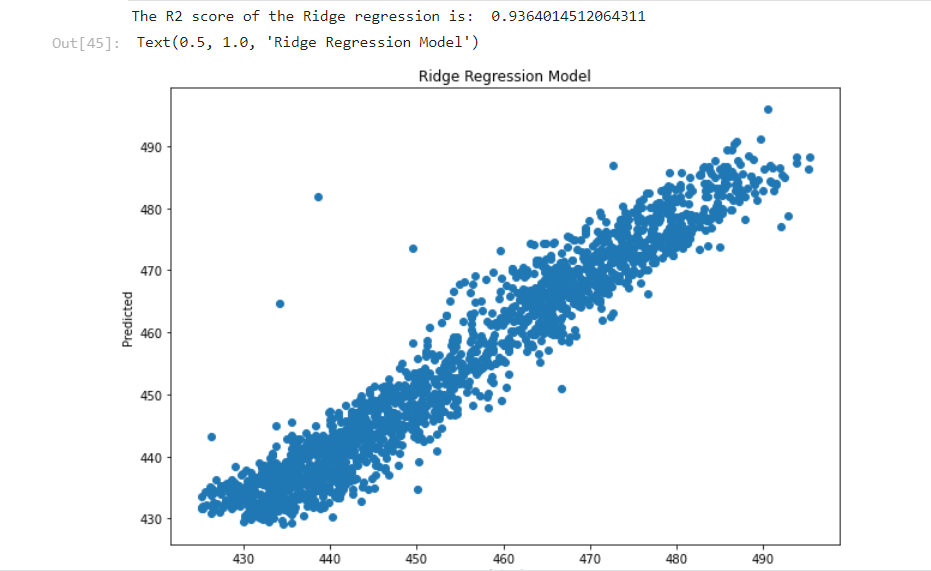
Results from the ridge regression model with a prediction accuracy of ~94%
OMDENA collaboration projects
Projects I was involved in as a Junior Machine Learning Engineer at Omdena
Project Title : Forecasting industrial CO2 using machine learning [Time series Forecasting]

Image source: OMDENA.com
Project Status: Completed
Background
Industrial carbon emissions is a significant environmental issue due to the large contribution of industrial processes to global emissions. The combustion of fossil fuels for energy generation, transportation, and manufacturing has resulted in several climate change and global warming issue. Therefore reducing industrial carbon emissions is now a critical challenge.
This project leverages machine learning (ML) techniques to predict and evaluate carbon emissions in various industries.
Collaborators : You can find all the collaborators in the project repository
Key technologies and skills : python, git, github, anaconda-jupyter, vscode, sklearn, matplotlib, jupyter, Pandas, numpy, matplotlib, streamlit
Method and working groups
Due to the nature of OMDENA projects, the working packages (tasks) are usually seperated into several groups.Task group– Data was responsible for finding suitable data for the project. The best data for our project was the OWID dataset. Data exploration was done and can be found. The Task group– Experimental Models developed several models to test for their performance and suitability for the project. The notebooks for the experimental models can be found in the group repository. The Task group– Model development developed several models, two notably were LSTM and Arima on the OWID dataset. The Task– model deployment used streamlit for model deployment.
My Contribution : I was part of the Task group– Data involved in research for a suitable data to be used in the project. I also used my domain knowledge in Environmental Science in processing and analyzing the data. I was also part of the Task group– Model development and created a Neural Prophet forecasting model with an MAPE accuracy of 0.01.
Project Title : Advanced weather forecasting with machine learning and python [Time series Forecasting]
 </p>
</p>
Image source: OMDENA.com
Project Status: Completed
Background
Between 1992 and 2021, climate- and weather-related disasters in Pakistan resulted in a total of US$29.3 billion of economic losses (inflation-adjusted to 2021 US dollars) from damage to property, crops, and livestock, equivalent to 11.1% of 2020 GDP.Over the same period, these disasters also caused the deaths of an estimated 20,000 people, and an estimated 10 million people have been displaced by weather-related disasters in Pakistan since 1992.
Accurate weather forecasts could help reduce these losses by providing early warning of hazardous weather conditions, allowing people to protect themselves and their property.
The goal of this project is to develop a machine learning model that can improve the accuracy of weather forecasts for Pakistan. The model will be trained on a dataset of historical weather data, and it will be able to predict future weather conditions with greater accuracy than current models.
Collaborators :You can find all the collaborators in this repository
Key technologies and skills : python, git, github, anaconda-jupyter, vscode, tensorflow, matplotlib, jupyter, Pandas, numpy, matplotlib, streamlit
Method and working groups
The Task group– Data collection collected the data from Open Meteo using requests and pandas library. The repo of the data collection group can be found in this subfolder. Full descrition of the parameters used in the model can be found in the README.md file of the project reository The Task group– Exploratory Data Analysis (EDA) performed EDA using descriptive and inferential statistics with the pandas library. Matplotlib and Seaborn libraries were primarily used for visualization. The notebooks for the EDA can be found in the task group repository. The Task group– Model development : models such as LSTM, Random Forest and ARIMAX were developed to forecast the different meterological parameters. Models of 30 days forecasts were created for the different meterological parameters. Random Forest was the best model with an accuracy up to 92%. The notebooks can be found in the Task group– model deployment.
My Contributions : In this project, I was part of the Task group– Model development developed a 30 days forecast model of precipitation using LSTM. I was also part of the Task group– model deployment and developed a streamlit app to host the models.
Challenges Faced during the project were data accessibility, and some models were not compartible with the streamlit app.
Project Title : Detecting microorganisms in water with deep learning [Object detection]
 </p>
</p>
Image source: OMDENA.com
Project Status: Completed
Background
United States does a very good job of providing clean and safe drinking water to most of its residents, but water borne diseases are becoming an increasing problem. According to the Centers for Disease Control (CDC), approximately 7.5 million waterborne illness occur annually, with a healthcare cost of about $3.3 billion. These infections result in emergency visits, hospitalizations, and deaths. These are caused by microorganisms, viruses, and fecal matter in the drinking water that are the result of an aging infrastructure, chlorine resistant pathogens, and finally an increase in recreational water use.
Key technologies and skills : python, git, github, anaconda-jupyter, vscode, tensorflow, matplotlib, jupyter, Pandas, numpy, matplotlib, streamlit, pytorch, docker, cv2, Roboflow, Google Drive, MS Office, DagsHub
Methods and task groups
Prior to the start of the project, the Project Manager already identified suitable data for the project.The data was the Environmental Microorganism Image Dataset Sixth Version (EMDS-6) and Environmental Microorganism Image Dataset Seventh Version (EMDS-7). The Task group– Data and research was responsible to check the usability of this data, and research for more data - since some classes of microorganisms (type of microorganism) had limited data count. Attached with the EMDS-7dataset is an object labelling file in .XML format. This file was not available for the EMDS-6 dataset, so it was created using the ‘Roboflow’software. A Microsoft Excel sheet was created as an input file to record the Microorganisms and their respective classes. This data was verified by an expert microbiologist. Task group – Exploratory Data Analysis (EDA) analysed the data using the cv2 module for image data, and pandas to create dataframes. Class and image dimension were checked for consistency. Matplotlib and Seaborn libraries were primarily used for visualization. The Task group– Model development developed baseline models using algorithms such as YOLOv8m-classification(classification), SSD(single-shot detector), EfficientNet, Faster R-CNN, Detectron2 (object detection) and compared based on performance and accuracy. The YOLOv8m-classification and Detectron2 were the best performing models. Task group– Model deployment deployed these two models on Streamlit. The Task group–Presentation was responsible for the documentation and presentation of the whole project thereby creating a starting point for the next phase (mobile app development)
Collaborators :You can find all the collaborators in the DagsHub repository
My Contribution I was art of two groups during the project. I helped in research for suitable additional microorganism data from the web as part of the Task group– Data and research. I also lead the Task group–Presentation and documentated the whole project.
The project blog can be found here
Project Title : Flood Guard: Integration of precipitation time series and GIS data for flood forecast in Bangladesh [Time series Forecasting]
 </p>
</p>
Image source: OMDENA.com
Project Status: Completed
Key technologies and skills : python, git, github, anaconda-jupyter, vscode, Google Earth Engine (GEE), tensorflow, matplotlib, jupyter, Pandas, numpy, matplotlib, streamlit, pytorch, Google Drive, MS Office, DagsHub
Background
Bangladesh is highly susceptible to flooding due to its unique geography and monsoon climate. Flooding leads to significant socio-economic and environmental consequences, causing the loss of lives, displacing communities, damaging infrastructure, and disrupting livelihoods. According to historical data from the Bangladesh Water Development Board (BWDB) and the Department of Disaster Management, flooding occurs annually during the monsoon season, affecting millions of people and causing substantial economic losses.
The goal of this project is to leverage time series rainfall data and Geographic Information System (GIS) data to develop a predictive model that can forecast flood occurrences and waterbody behavior across Bangladesh
Collaborators : You can find all the collaborators in the DagsHub repository
Methods and task groups
Task group– Knowledge : was responsible for research of articles for data models and techniques.The Task group– Data and research : extracted GIS and CSV data using Google Earth Engine platform. The extracted data and scripts used for this project are found here.Task group– Exploratory Data Analysis (EDA) : performed EDA using the numpy and pandas libraries, with support of the Matplotlib and Seaborn libraries for visualization. The notebooks for the EDA can be found here in this repo. The [Task– Model development :]https://dagshub.com/Omdena/BangladeshChapter_FloodGuard/src/main/src/tasks/task-3-fe-and-model-development developed baseline models such as Sequential, Conv1D, LSTM, RNN, LSTM. Layers and parameters were modified to increase the accuracy of the models. The developed models can be found here in the repo. The [Task– Model deployment] deployed was LSTM - which was the best performing model, using Streamlit app. The deployed model can be found here in this repo.
My Contribution : I was actively involved in the Task group– Data and research to research on articles to identify suitable data, models and evaluate their documented performances for the project.